In particular, check out Lua Carousel, a lightweight programming environment for desktop and mobile devices.
I build Freewheeling Apps, computer programs that reward curiosity.
Other Projects and Writings
Mar 13, 2024
Sokoban
The kids have been enjoying Baba is You, and watching them brought back pleasant memories for me of playing the classic crate-pushing game Sokoban. So I went looking and found a very nice project that has collected 300 classic publicly available Sokoban puzzles. Then of course I had to get it on my phone so I could play it anywhere. The result is the sokoban.love client.
video; 1 minute
Read more →
* *
Feb 20, 2024
rabbot.love
rabbot.love is a little helper I whipped up to check the programs the kids were writing for a neat little paper computer.
video; 25 seconds
* *
Nov 23, 2023
Lua Carousel
I finally decided to hang up a shingle on itch.io. My first app there is not a game. Lua Carousel is a lightweight environment for writing small, throwaway Lua and LÖVE programs. With many thanks to Mike Stein who helped me figure out how to get it working on iOS, this is my first truly cross-platform app, working on Windows, Mac, Linux, iOS and Android.
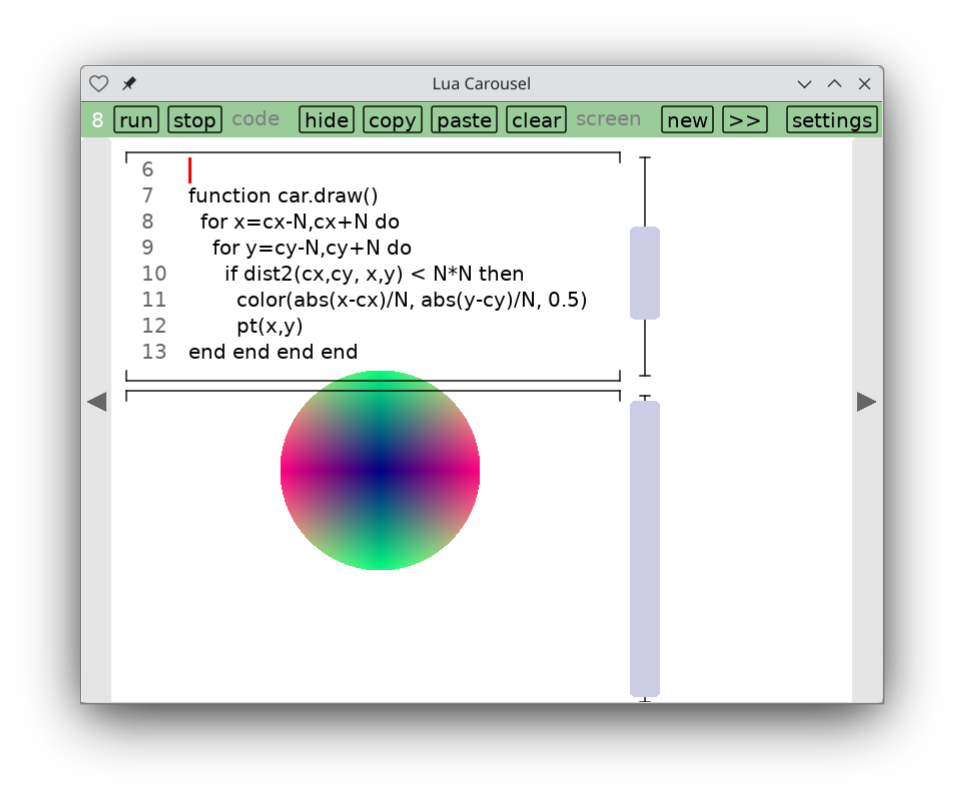
* *
Nov 16, 2023
sum-grid.love
A little sudoku-like app for helping first-graders practice addition. This attempt at situated software for schooling got a little more use than spell-cards.love.
video; 25 seconds
* *
Oct 18, 2023
crosstable.love
crosstable.love is a little app I whipped up for tracking standings during the Cricket World Cup, just to avoid the drudgery of resorting rows as new results come in.
video; 20 seconds
* *
Aug 22, 2023
Quickly make any LÖVE app programmable from within the app
It's a very common workflow. Type out a LÖVE app. Try running it. Get an error, go back to the source code.
How can we do this from within the LÖVE app? So there's nothing to install?
This is a story about a hundred lines of code that do it. I'm probably not the first to discover the trick, but I hadn't seen it before and it feels a bit magical.
* *
Jul 2, 2023
A simple app for drawing Wardley Maps
wardley.love is a reskin of snap.love for drawing Wardley Maps. I've been using it a lot; here's one example:
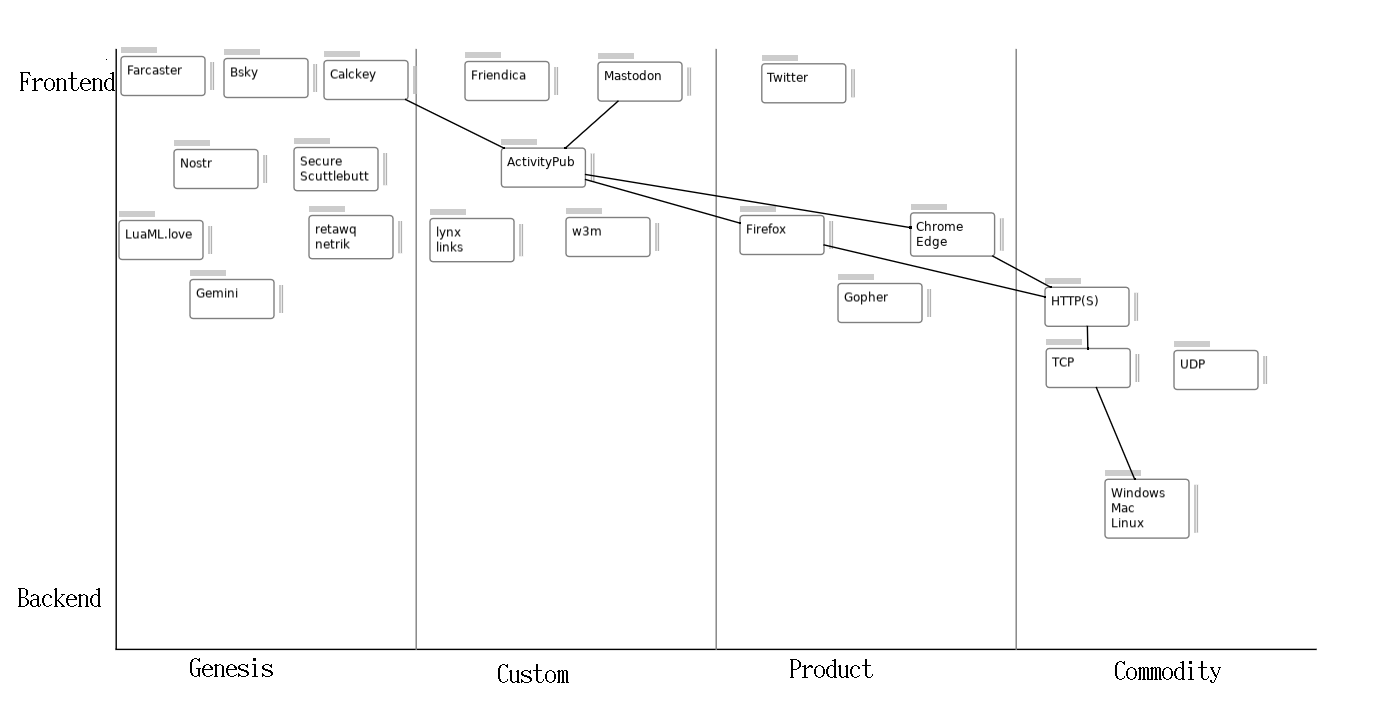
* *
Jun 28, 2023
pothi.love
I love reading Kragen Sitaker as an endless fount of surprisingly deep programs and analysis. Lately he's been avoiding the web and writing in a directory of markdown files. He writes so much that he switches directories every year or so (I think of them as volumes), and they're all highly recommended for sifting through during quiet afternoons:
pothi.love
is a simple browser for such a directory of files that lets me add comments
locally to them. Then I can git commit and git push
to publish them.
(The name: 'pothi' is Sanskrit for a sort of loose-leaf book of palm leaves, 'bound' with a single string through a single hole in the middle of each page/leaf.)
* *
May 23, 2023
Using computers more freely and safely
* *
Apr 21, 2023
snap.love
snap.love is a graph-drawing app that gets closest to what I want when I want to draw boxes and arrows. Unlike Graphviz and PlantUML, this tool is for small graphs where you want complete control over layout. Unlike PowerPoint or draw.io, this tool results generates text files that are more amenable to version control. The catch: it's a lot more limited than all these tools; all you can do so far is draw rectangles and edges between them.
* *