Six months ago I fell into a little gig to teach two students programming, and it's been an eye-opening experience. Where I was earlier focused on conveying codebases to programmers, I've lately been thinking a lot harder about conveying programming to non-programmers. I think the two might be special-cases of a grand unifying theory of software representation, but that's another story. For now I don't have a grand unifying theory. What I have is a screenshot:
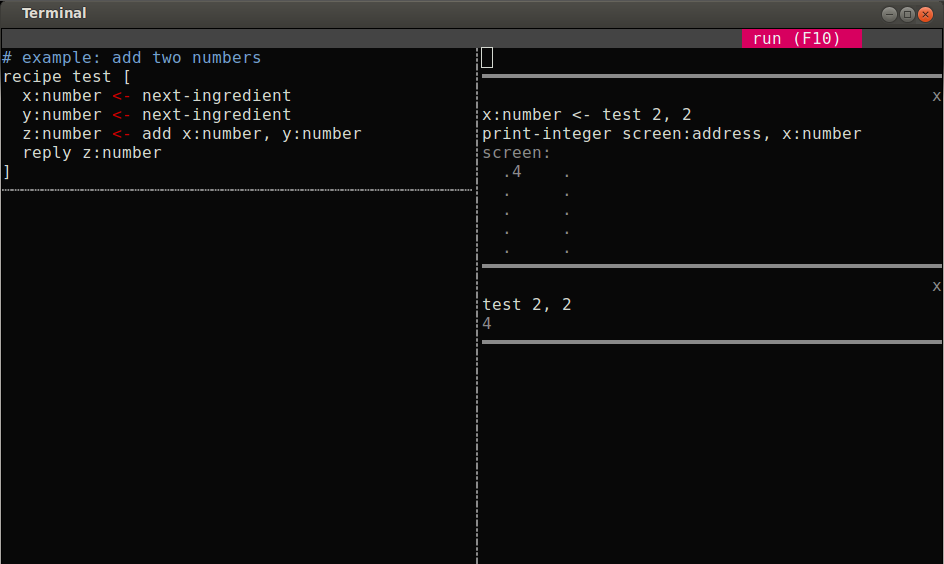
Let me describe the tool and the problems that it tries to address. When I started out teaching I picked an existing platform that I'd always liked. But quickly I started noticing many limitations. Today's platforms are great for experienced programmers and one can do great things with them, but they are very alien to noobs, who suddenly have to learn many different things at once.
Memorizing unfamiliar terminology
Functions, arguments, classes, methods, objects, threads, locks, all these are reassuring everyday words, and yet their meaning in programming (and math) bears no relation to their everyday meaning. The choices of names cause learning strange concepts to be preceded by a wholly unnecessary step of unlearning, to weaken the connection between the words and their meanings.
Instead of using these words I've tried to replace them with new ones that bear some intuitive resemblance with their everyday meanings, or at least that don't have distracting everyday meanings. I call functions recipes, and function arguments ingredients. Each recipe consumes some ingredients and generates some products. Along the way it may need other intermediate reagents, which have their own recipes for production. Records are called containers, and their fields are elements. Unions are called exclusive containers rather than sum types. This is all still experimental. I want to avoid just moving names around and adding to the tower of babel, so if I can't find a connotation-free name I just go with existing conventions.
Motor control
Programmers use some specialized tools. For most languages, you usually want some sort of automatic indentation, the ability to highlight comments so you can tell what won't run, to balance brackets and spot unbalanced ones, and so on. All these conveniences are particularly important to neophytes, who haven't yet learned to micromanage their text and are most likely to end up with strange configurations of characters early on. But learning specialized programmer tools is non-trivial, particularly when also trying to learn programming at the same time. Ever-present is the danger of putting off the hard problem of programming in favor of more pleasant yak-shaves like trying out editors, reading about their pros and cons, and so on. Added to these, my students were remote and we would videoconference for lessons, which introduced all the complexities of screen-sharing. They would write code in files, and then struggle to iteratively try out twenty different variations on them. Or they would start out at an interactive prompt and struggle to get their code out to some persistent form and not lose their work. Copy pasting is non-trivial in the presence of multiple windows in a terminal. We had to zoom one window in to fill the whole screen, copy, zoom back out, switch windows, paste. Over and over and over again.
In response, my UI provides a place for writing code on the left, and a place to try it out on the right. Every command run always picks up the most recent changes. No pasting or switching between environments. The editor is in text mode so that we can run it over tmux and conserve our bandwidth for audio or video. It's pretty rudimentary, but it's meant to be grown out of.
Discerning structure and patterns in code
Last year this graph went around the internet, showing how the number of women programmers began to drop off in the mid-80s:
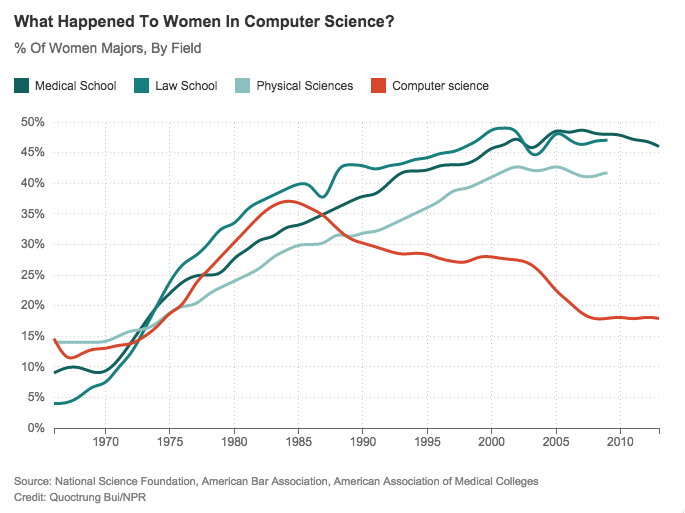
I was recently struck by a vague correlation: that's around the time we stopped programming in Assembly! I don't have hard data on this, and it's before my time, but my sense is that for a long time high-level languages were just too rare and inaccessible for most beginning programmers. The Commodore-64 came out in 1982 but came with Basic, which was quite low-level (you couldn't declare function arguments). Turbo Pascal came out in 1983 but you had to pay for it. The Amiga came out in 1985 and started to get high-level language tooling around 1988 or so. Linux didn't start until 1991, bringing free GNU tools to a wider audience. Squinting at these data points I surmise that somewhere in the decade starting 1982, high-level 'structured' languages went mainstream and Assembly programmers finally started to die out. Perhaps it's not accidental that that was when the demographics started to shift at the top of the funnel? Perhaps there was something about high-level languages that added an extra layer of complexity early on, and made programming harder to learn. I think it might have been the syntax. Syntax is finicky. I've given two dozen non-programmers the hour of code challenge, and for all of its undeniable polish almost all of them repeatedly confuse the two lower surfaces of blocks like these:

It turns out to take spaced repetition to internalize that inside and outside are different places. Even in a language designed from scratch (pun intended) to minimize syntax errors, we see the reason they happen in its essence.
The difficulty gets more obvious in other languages. I love Lisp, but it takes spaced repetition to internalize why this code runs from 'bottom to top':
(cons (car list) (insert x (cdr list)))
while this one runs top to bottom:
(foo a) (bar b) (baz c)
Whether it's Lisp or Ruby, putting something before or after a bracket has enormous import in programming. Can we minimize the number of brackets and nested structures needed to write programs? My UI introduces a bare-bones Assembly-like language where recipes are always sequences of instructions, and instructions are always one to a line:
recipe foo [ instruction 1 instruction 2 ]
In spite of seeming like Assembly or Basic, the language supports higher-order generic functions, literate tangling (labels turn out to make great markers for inserting code), first-class delimited continuations (which turn out to be extremely easy to represent as localized operations on the call-stack) and much more. It's designed to be extremely easy to compile, exposing the burden of all optimization to the user while allowing great control of the entire stack.
Managing multiple namespaces
Look again at that recipe above. Just sequences of instructions, hmm, how does it take arguments? Specify their types? This question gets at another issue that repeatedly throws people in my experience. Functions usually look like this:
function foo(a, b, c): ...
..and get called like this:
foo(x, y, z)
Crucially, the values of their arguments have different names outside and inside the function, so learners have to juggle twice the number of names. Confusion ensues: callee names get used at the call-site, caller names inside the callee, and all combinations thereof. I don't think anybody has discussed this before (pointers most appreciated). Even Seymour Papert — for all his pioneering work in making the steps of a computation concrete — continued to use traditional function definitions and arguments very similar to those above in his Logo language. Scratch and Blockly have followed in the same vein.
I'm planning to try something slightly different with my students. Instead of just packing all the information about a function's arguments and return values into a single line, my language sets up a conceptual pipe between every call-site and its recipe, using a primitive called next-ingredient to read each ingredient separately from the pipe and bind it explicitly to a new name. In addition to staging the introduction of new names, this approach is powerful enough to support optional arguments, variadic functions and much more besides.
# recipe expecting one ingredient recipe foo [ x:number <- next-ingredient ...use x... ]
(Mu does support function headers and argument lists. I just don't use them when first teaching functions.)
Juggling multiple scenarios
In my lessons, this pattern constantly happens. I set my students an exercise. “Write a recipe that ___.” They set to work, quickly come up with an answer, try it out on a test input, go back and tweak, get it working, and tell me they're done. I look at their solution and say, “what about if you call it with ____?” Oops. Off they go to fix the new scenario, but when they succeed they've often broken their original scenario, which lies forgotten somewhere above in the scrollback buffer. Often they ping-pong between regressions. In their brownian motion I remember my own experiences; I used to do the same thing for many years. What finally cured me of this pattern was writing tests.
My UI contains a rudimentary way to get them thinking about tests, in particular to focus on the intangible space of inputs around a recipe rather than just the tangible code inside it. Here's how it works: everytime they run a command on the right hand side, the UI reruns every command they've run so far. I'm working on adding color into the mix, so that they can click on a result to label it green/expected, and so that any changes in the result turn it red. The hope is that automatically rerunning scenarios will draw attention to them and gradually give them space in the head while programming.
Each of the scenarios runs in an isolated sandbox (hence the solid horizontal lines) but shares all code on the left (hence the dotted vertical line). Sandboxes are extremely lightweight virtual machines with their own screen, keyboard and mouse (and, in the future, networking and disk storage and more). Look again at the screenshot at the top of the page. There are two sandboxes. One returns its result, while the other prints it to a tiny simulated screen, delimited by dots. Mu the language supports a lot more. You can run a recipe, then check that the contents are what you expect. You can fill a keyboard buffer with characters and check that they're processed as expected. These features are already used to build Mu the UI in Mu the language, over the course of 77 tests, but they aren't fully supported in the UI yet.
Coda
When I think back to all my different teaching experiences, one over-arching pattern dominates: people are very good at programming when you teach them in person. They pick up concepts quickly, they surprise you with their leaps of logic and intuition. But leave them alone and the vast majority tend to subside. I've repeatedly shown them the mechanics, but I've often failed to “kindle their longing for the endless possibilities of this strange new universe.” (With apologies to Antoine de Saint-Exupéry.) This is the hard problem of teaching programming today: to go from conveying mechanics to achieving a sort of ‘lift-off’ where they're on a self-sustaining trajectory of learning by doing. We'll see if these ideas of mine help. I'm about to try them out on my students. I'll report back and, if they're promising, start to add more students.
(This article is derived from a talk presented at the Bay Area Lisp meetup.)
comments
Comments gratefully appreciated. Please send them to me by any method of your choice and I'll include them here.
It's not much of a gotcha when students have you to nudge them in the right direction. I didn't mean to criticize Scratch. I quite appreciate how it helped me understand this core skill to teach in programming. So don't change anything about how you work with them, just come back and tell me if they ran into the inside/outside confusion, and how many nudges they needed before they stopped making that mistake :)
(Since it's a prototype it's definitely not compatible with the current version.)