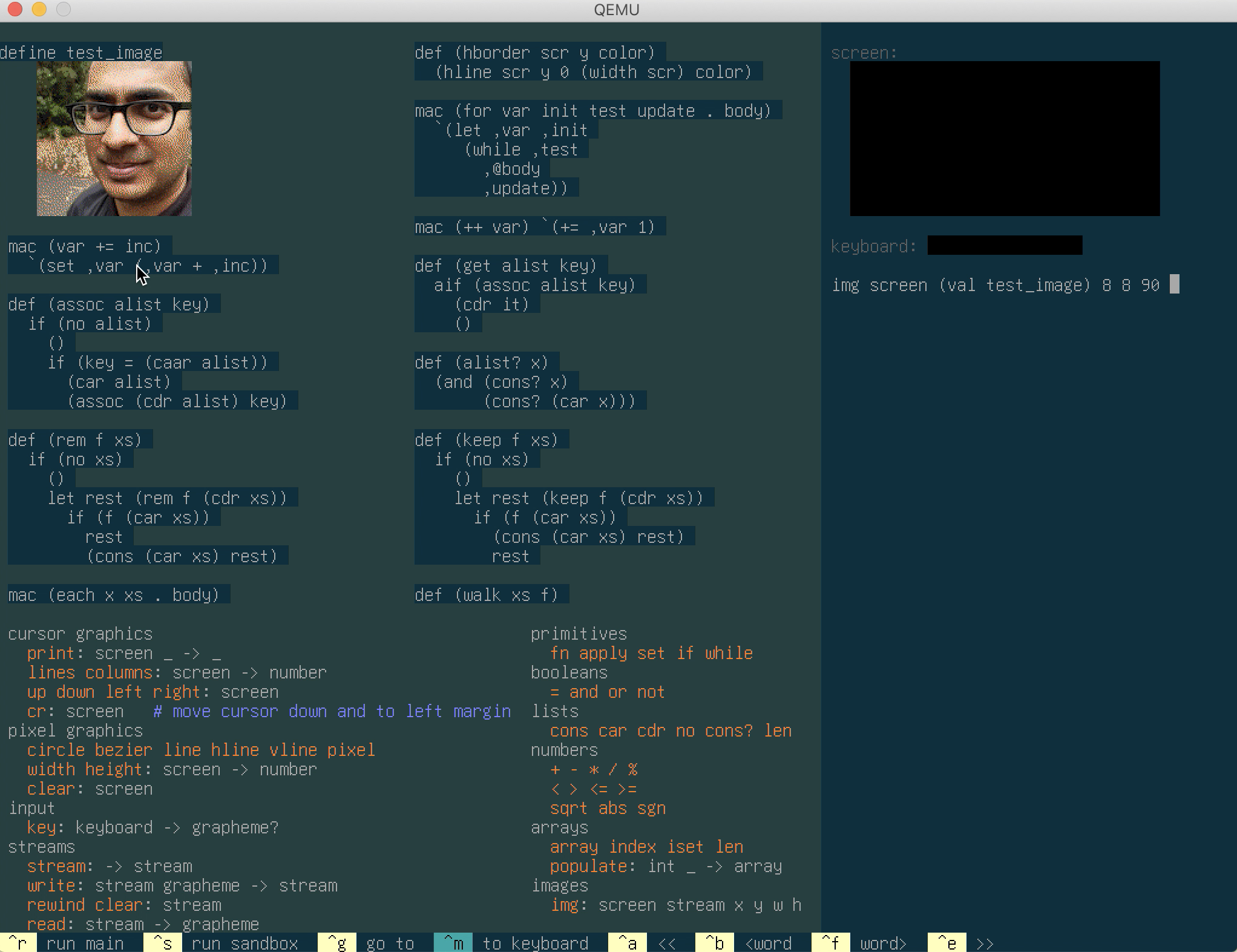
The Mu computer now loads 140KB of Unicode glyphs from its system font
Unicode blocks now supported: latin, greek, cyrillic, armenian, hebrew, arabic, syriac, thaana, n'ko, indian (ISCII), sinhala, thai, lao, tibetan, myanmar, georgian (< U+1100)
Caveats:
No support for combining characters yet (https://en.wikipedia.org/wiki/Combining_character) This makes the other languages I know (Hindi, Tamil) well-nigh useless.
Unifont's glyphs for the non-Latin languages I know turn out to be quite spectacularly ugly.
A lot gets said about simplicity in software, about essential vs accidental complexity. If you really want a simple stack that empowers everyone, it isn't enough to just eliminate accidental complexity (even if we could all agree on what it is). You need to also avoid other people's essential complexity.
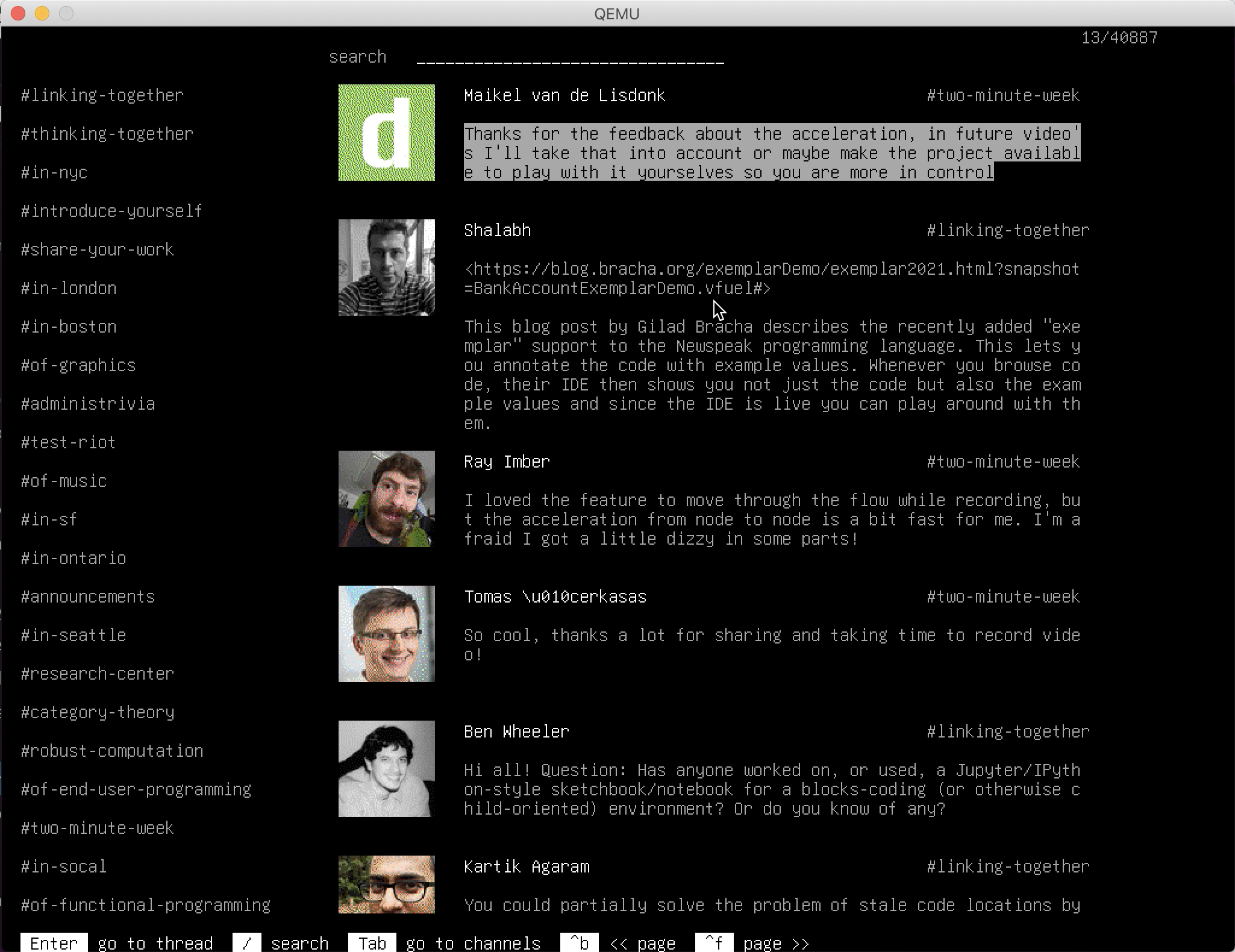
It's amazing how fast computers are. Before I took the trouble to build a search index I figured I'd try the simplest possible way to search every single post and comment of 5 years of archives of a fairly active community. 150MB of text.
It's instantaneous.
Running emulated on Qemu. Without any acceleration.
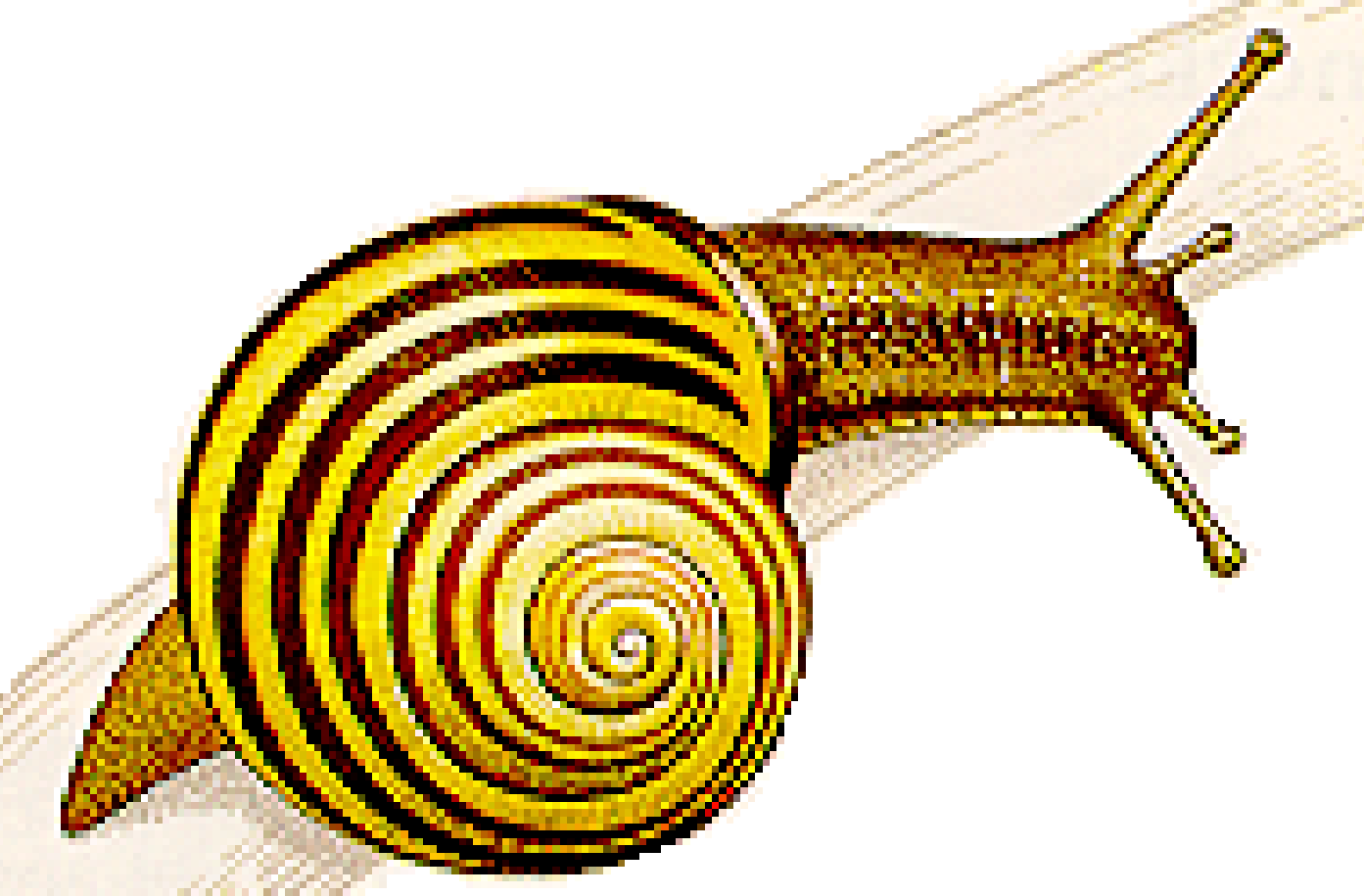
Here is a before/after pair of images. Before has 256x256x256 colors. After
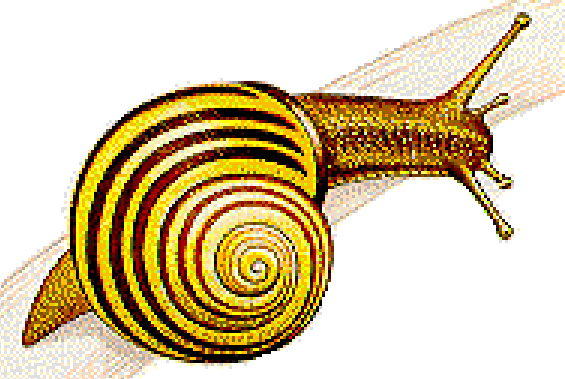
has 256 colors.
Before:
After:
Notice all the yellow pixels in the first image that turn into alternating greens and oranges in the second. Also, the stem looks very different. But overall, it looks gratifyingly similar to the original. My eyes took a while before they started to notice differences.
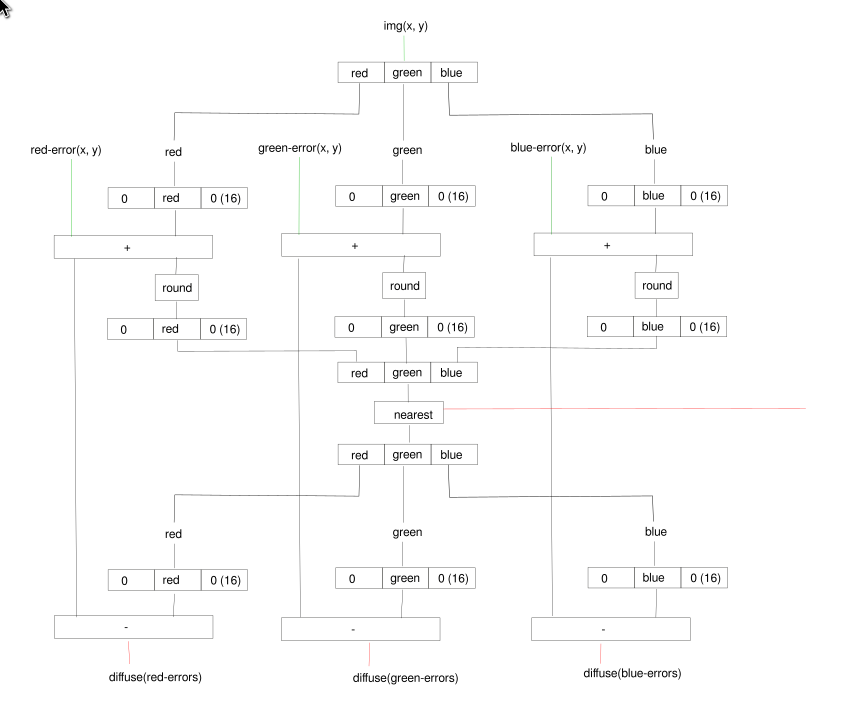
Generalizing dithering to color (assuming a fixed palette) turns out to be surprisingly complex. The r/g/b channels are mostly independent copies each analogous to the greyscale dither, but there's tangling in one place in the center that complicates everything.