In particular, check out Lua Carousel, a lightweight programming environment for desktop and mobile devices.
I build Freewheeling Apps, computer programs that reward curiosity.
Other Projects and Writings
May 19, 2026
Updating a mantra from 2007
Me in 2007: Building something is easy. Evaluating what you build is hard. Iterate between the two as fast as you can.
Stefan Lesser in 2023 (paraphrased): Building helps understand ourselves through the world, and understand the world through ourselves.
Me now: Building things is easy. Evaluating what you build is hard. It requires lots of attention. Therefore, build things that you want to pay lots of attention to.
* *
Mar 29, 2025
A markup language and hypertext browser in 600 lines of code
Here's a document containing a line of text:
{type='text', data={'hello, world'}}
I'm building in Lua, so I'm reusing Lua syntax. Here's how it looks:

Such text boxes are the workhorse of this markup language. There are 3 other kinds of boxes: rows, cols and filler. Rows and cols can nest other boxes. But let's focus on text boxes for a bit.
Read more →
* *
Jan 31, 2025
Practicing graphical debugging using too many visualizations of the Hilbert curve
Sorry, this article is too wide for my current website design so you'll need to go to it →

* *
Jul 31, 2024
How I program in 2024
I talk a lot here about using computers freely, how to select programs to use, how to decide if a program is trustworthy infrastructure one can safely depend on in the long term. I also spend my time building such infrastructure, because there isn't a lot of it out there. As I do so, I'm always acutely aware that I'm just not very good at it. At best I can claim I try to compensate for limited means with good, transparent intentions.
I just spent a month of my free time, off and on, rewriting the core of a program I've been using and incrementally modifying for 2 years. I've been becalmed since. Partly this is the regular cadence of my subconscious reflecting on what just happened, what I learned from it, taking some time to decide where to go next. But I'm also growing aware this time of a broader arc in my life: Read more →
* *
Mar 13, 2024
Sokoban
The kids have been enjoying Baba is You, and watching them brought back pleasant memories for me of playing the classic crate-pushing game Sokoban. So I went looking and found a very nice project that has collected 300 classic publicly available Sokoban puzzles. Then of course I had to get it on my phone so I could play it anywhere. The result is the sokoban.love client.
video; 1 minute
Read more →
* *
Feb 20, 2024
rabbot.love
rabbot.love is a little helper I whipped up to check the programs the kids were writing for a neat little paper computer.
video; 25 seconds
* *
Nov 23, 2023
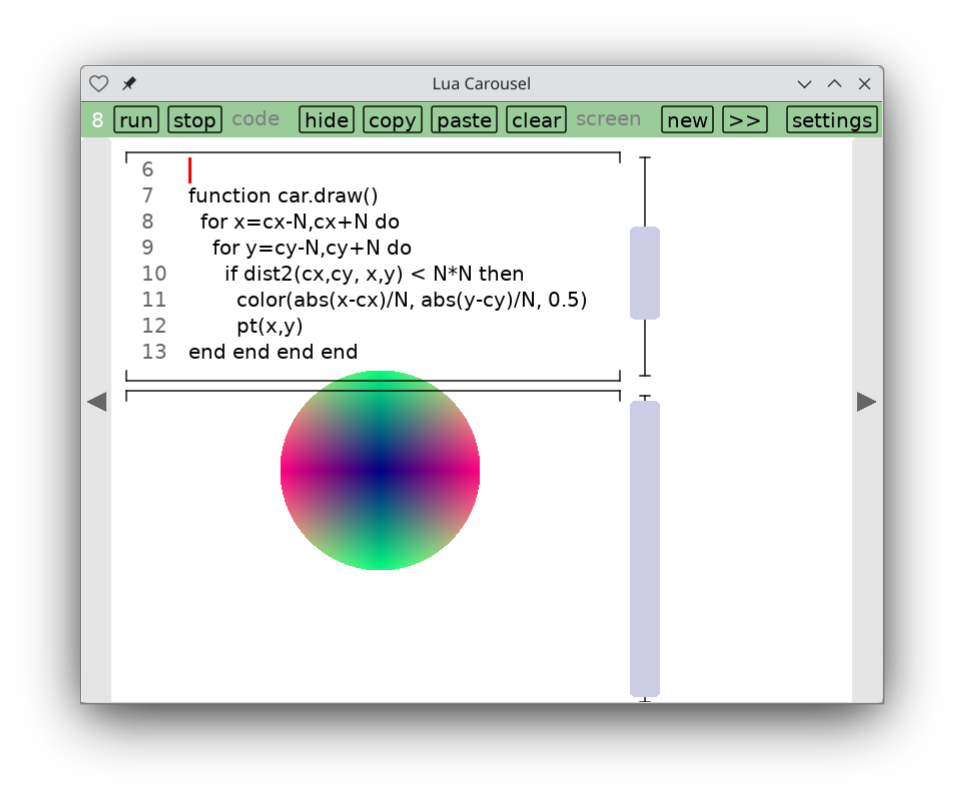
Lua Carousel
I finally decided to hang up a shingle on itch.io. My first app there is not a game. Lua Carousel is a lightweight environment for writing small, throwaway Lua and LÖVE programs. With many thanks to Mike Stein who helped me figure out how to get it working on iOS, this is my first truly cross-platform app, working on Windows, Mac, Linux, iOS and Android.
* *
Nov 16, 2023
sum-grid.love
A little sudoku-like app for helping first-graders practice addition. This attempt at situated software for schooling got a little more use than spell-cards.love.
video; 25 seconds
* *
Oct 18, 2023
crosstable.love
crosstable.love is a little app I whipped up for tracking standings during the Cricket World Cup, just to avoid the drudgery of resorting rows as new results come in.
video; 20 seconds
* *
Aug 22, 2023
Quickly make any LÖVE app programmable from within the app
It's a very common workflow. Type out a LÖVE app. Try running it. Get an error, go back to the source code.
How can we do this from within the LÖVE app? So there's nothing to install?
This is a story about a hundred lines of code that do it. I'm probably not the first to discover the trick, but I hadn't seen it before and it feels a bit magical.
* *