Mar 23, 2020
The Mu compiler summarized in one page
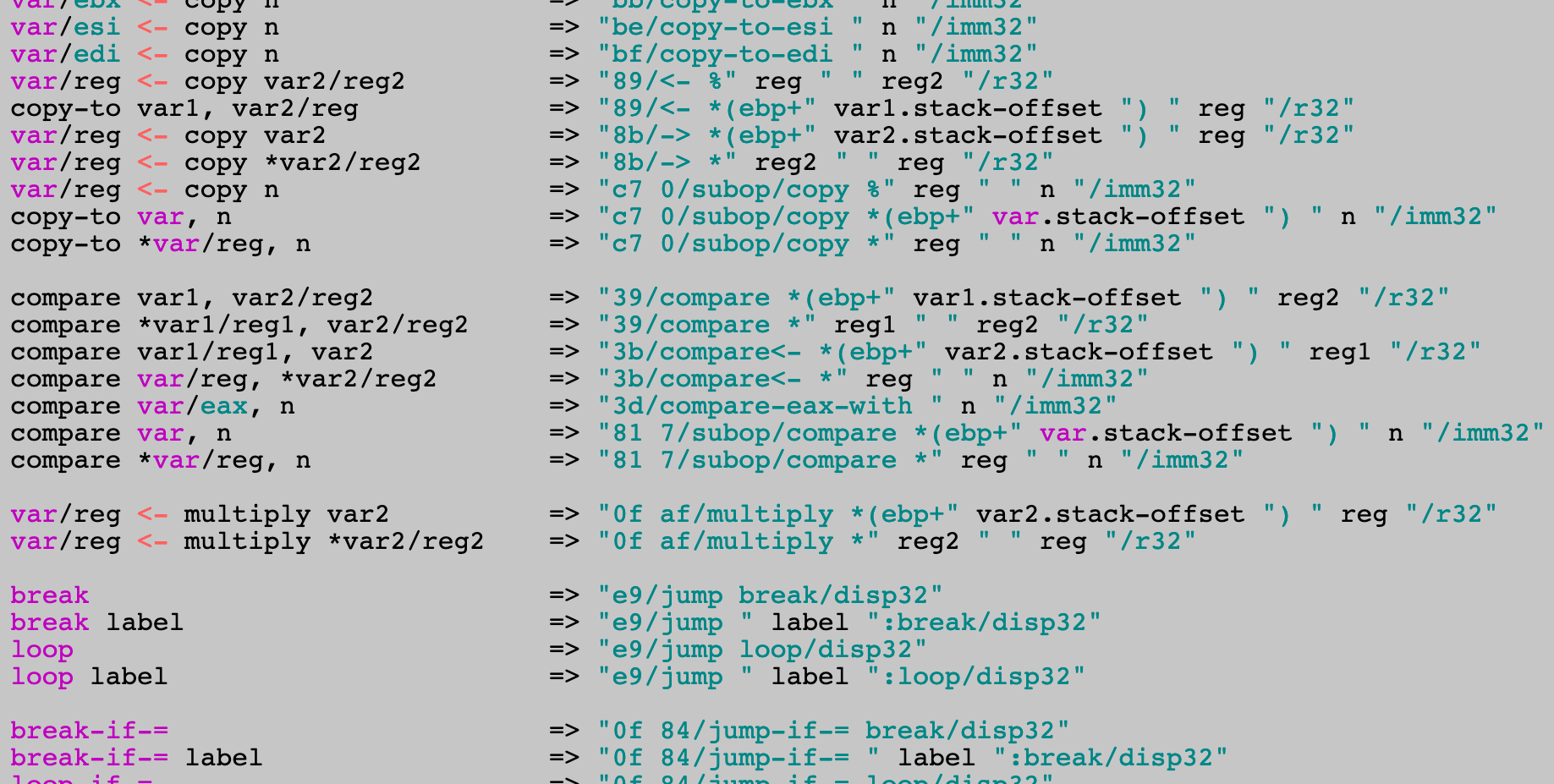
More details
Repo
(Brief update since there isn't much to report: I'm working on safe heap allocations as described in the paper. But it's slow going because of life and the need to unwind some past decisions.)
permalink
* *
Mar 16, 2020
I'm hitting publish on my paper.
Kartik Agaram, "Bicycles for the mind have to be see-through", Convivial Computing Salon, 2020.
http://akkartik.name/akkartik-convivial-20200315.pdf [pdf; 25 pages]
Get it? When I look over at my bicycle I can see right through its frame. I can take in at a glance how the mechanism works, how the pedals connect up with the wheels, and how the wheels connect up with the brakes. And yet, when we try to build bicycles for the mind, we resort to “hiding” and “abstraction”.
permalink
* *
Mar 12, 2020
Programming in 2D text
This evening I'm thinking of two ideas I've thought about several times before, but never together.
The first: Arjun Nair's IRCIS, an esoteric language (art for art's sake) that comes with a cool visualizer. Maybe all languages should.

The second is Dave Ackley's Movable Feast Machine, a tiled processor for very finely grained distributed computation. Programming it is like playing with a cellular automaton.
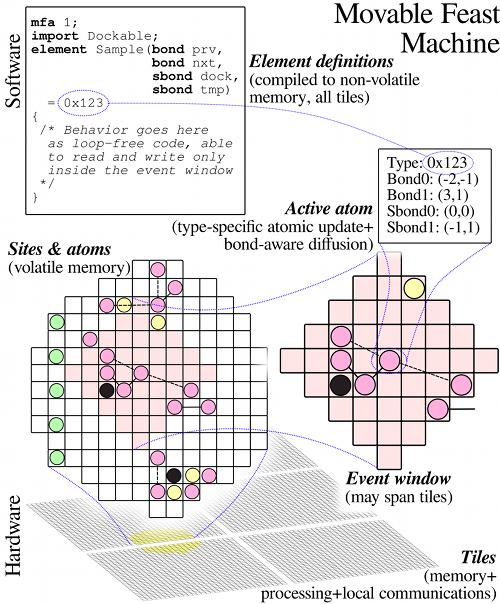
The two projects have very different goals. IRCIS seems to be just a fun hack. MFM explores ideas for scalable, robust, secure computation.
Today I'm wondering if putting them together might get us a way to gradually learn programming that rivals spreadsheets.
What if we expand IRCIS from 1x1 to 1x2. The cursor occupies 2 characters, one data and one code. The cursor has modes that operate on data or code, independently. The same path may do different things depending on the mode.
Another mode idea: push characters like sokoban.
The immediate goal is to do something non-trivial, like say tokenizing a string into words. Or maybe a 4-operation arithmetic evaluator? And, crucially, for the grid to go with the grain of the visual cortex. Amenable to visual inspection, encouraging self-documenting programs.
permalink
* *
Mar 12, 2020
Update on the Mu computer's memory-safe language
Arrays and product types are now done. Any remaining rough edges are working as intended 😄 Only hex literals, for example.
What's left? Actually making it safe.
Complexity outlay so far: 16k lines of code, but only 6.5k if you exclude tests. Tests get _very_ repetitive in machine code. Hopefully we won't need another 15k LoC.
Example program
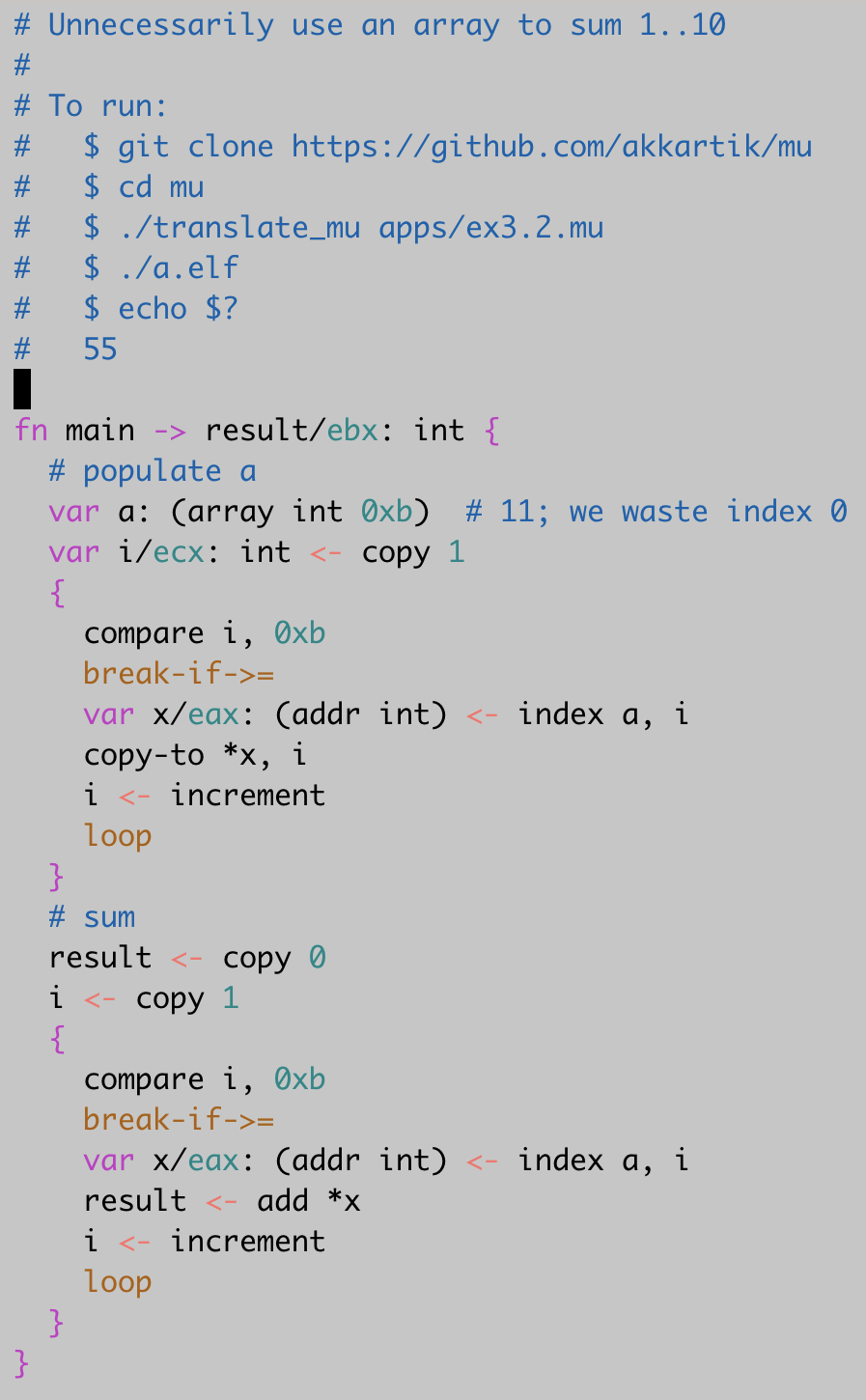
(More details. Repo.)
permalink
* *
Mar 8, 2020
New milestone: I just wrote 150 LoC of glorified machine code (utterly unsafe; lots of magic numbers) and had it work the first time.
https://github.com/akkartik/mu/commit/c8784d1c0f0
Though to be fair I'd been planning it for 16 hours, with lots of preliminary commits that nibbled away at the edges of the problem. Still, time spent thinking before rather than debugging after.
Perhaps this is bad news. Perhaps my brain is getting so colonized by machine code that I'm losing my bearings on what is easy for others.
permalink
* *
Mar 6, 2020
Lots of words in
this commit message about liveness analysis, and it probably still makes no sense to anybody.
Hopefully it'll make sense to me at least in a month or two.
permalink
* *
Feb 28, 2020
OMG, check out this "spiritual fork" of Mu that's designing not just the entire software stack to fit in a single person's head, BUT ALSO THE PROCESSOR.
https://github.com/grokthis/ucisc/blob/master/docs/01_Introduction.md
Still super early days. There's a nascent VM.
Needless to say, I'll be contributing.

permalink
* *
Feb 28, 2020
Update on the Mu computer's memory-safe language
Still no type-checking or memory-safety, but we have partial support for arrays and product types. Still several sharp edges:
- can't index an array with a literal
- can't index an array with non-power-of-2-sized elements
- can allocate but not use arrays/records on the stack
My todo list is growing. But work per item is shrinking. Hopefully there's an asymptote.
(More details. Repo.)
permalink
* *
Feb 21, 2020
Update on the Mu computer's memory-safe language
Mu just got its first couple of non-integer types: addresses and arrays. As a result, the factorial app can finally run its tests based on command-line args.
http://akkartik.github.io/mu/html/apps/factorial.mu.html
Addresses are accessed using a '*' operator. Arrays are accessed using an index instruction that takes an address (addr array T) and returns an address (addr T).
Literal indexes aren't supported yet.
Open question: indexing arrays of non-power-of-2 element sizes.
permalink
* *